Как рассчитать коэффициент корреляции в Excel. Проверка простых гипотез критерием хи-квадрат Пирсона в MS EXCEL
Рассмотрим применение в MS EXCEL критерия хи-квадрат Пирсона для проверки простых гипотез.
После получения экспериментальных данных (т.е. когда имеется некая выборка ) обычно производится выбор закона распределения, наиболее хорошо описывающего случайную величину, представленную данной выборкой . Проверка того, насколько хорошо экспериментальные данные описываются выбранным теоретическим законом распределения, осуществляется с использованием критериев согласия . Нулевой гипотезой , обычно выступает гипотеза о равенстве распределения случайной величины некоторому теоретическому закону.
Сначала рассмотрим применение критерия согласия Пирсона Х 2 (хи-квадрат) в отношении простых гипотез (параметры теоретического распределения считаются известными). Затем - , когда задается только форма распределения, а параметры этого распределения и значение статистики Х 2 оцениваются/рассчитываются на основании одной и той же выборки .
Примечание : В англоязычной литературе процедура применения критерия согласия Пирсона Х 2 имеет название The chi-square goodness of fit test .
Напомним процедуру проверки гипотез:
- на основе выборки вычисляется значение статистики , которая соответствует типу проверяемой гипотезы. Например, для используется t -статистика (если не известно);
- при условии истинности нулевой гипотезы , распределение этой статистики известно и может быть использовано для вычисления вероятностей (например, для t -статистики это );
- вычисленное на основе выборки значение статистики сравнивается с критическим для заданного значением ();
- нулевую гипотезу отвергают, если значение статистики больше критического (или если вероятность получить это значение статистики () меньше уровня значимости , что является эквивалентным подходом).
Проведем проверку гипотез для различных распределений.
Дискретный случай
Предположим, что два человека играют в кости. У каждого игрока свой набор костей. Игроки по очереди кидают сразу по 3 кубика. Каждый раунд выигрывает тот, кто выкинет за раз больше шестерок. Результаты записываются. У одного из игроков после 100 раундов возникло подозрение, что кости его соперника – несимметричные, т.к. тот часто выигрывает (часто выбрасывает шестерки). Он решил проанализировать насколько вероятно такое количество исходов противника.
Примечание : Т.к. кубиков 3, то за раз можно выкинуть 0; 1; 2 или 3 шестерки, т.е. случайная величина может принимать 4 значения.
Из теории вероятности нам известно, что если кубики симметричные, то вероятность выпадения шестерок подчиняется . Поэтому, после 100 раундов частоты выпадения шестерок могут быть вычислены с помощью формулы
=БИНОМ.РАСП(A7;3;1/6;ЛОЖЬ)*100
В формуле предполагается, что в ячейке А7 содержится соответствующее количество выпавших шестерок в одном раунде.
Примечание : Расчеты приведены в файле примера на листе Дискретное .
Для сравнения наблюденных (Observed) и теоретических частот (Expected) удобно пользоваться .

При значительном отклонении наблюденных частот от теоретического распределения, нулевая гипотеза о распределении случайной величины по теоретическому закону, должна быть отклонена. Т.е., если игральные кости соперника несимметричны, то наблюденные частоты будут «существенно отличаться» от биномиального распределения .
В нашем случае на первый взгляд частоты достаточно близки и без вычислений сложно сделать однозначный вывод. Применим критерий согласия Пирсона Х 2 , чтобы вместо субъективного высказывания «существенно отличаться», которое можно сделать на основании сравнения гистограмм , использовать математически корректное утверждение.
Используем тот факт, что в силу закона больших чисел наблюденная частота (Observed) с ростом объема выборки n стремится к вероятности, соответствующей теоретическому закону (в нашем случае, биномиальному закону ). В нашем случае объем выборки n равен 100.
Введем тестовую статистику , которую обозначим Х 2:

где O l – это наблюденная частота событий, что случайная величина приняла определенные допустимые значения, E l – это соответствующая теоретическая частота (Expected). L – это количество значений, которые может принимать случайная величина (в нашем случае равна 4).
Как видно из формулы, эта статистика является мерой близости наблюденных частот к теоретическим, т.е. с помощью нее можно оценить «расстояния» между этими частотами. Если сумма этих «расстояний» «слишком велика», то эти частоты «существенно отличаются». Понятно, что если наш кубик симметричный (т.е. применим биномиальный закон ), то вероятность того, что сумма «расстояний» будет «слишком велика» будет малой. Чтобы вычислить эту вероятность нам необходимо знать распределение статистики Х 2 (статистика Х 2 вычислена на основе случайной выборки , поэтому она является случайной величиной и, следовательно, имеет свое распределение вероятностей ).
Из многомерного аналога интегральной теоремы Муавра-Лапласа известно, что при n->∞ наша случайная величина Х 2 асимптотически с L - 1 степенями свободы.
Итак, если вычисленное значение статистики Х 2 (сумма «расстояний» между частотами) будет больше чем некое предельное значение, то у нас будет основание отвергнуть нулевую гипотезу . Как и при проверке параметрических гипотез , предельное значение задается через уровень значимости . Если вероятность того, что статистика Х 2 примет значение меньше или равное вычисленному (p -значение ), будет меньше уровня значимости , то нулевую гипотезу можно отвергнуть.
В нашем случае, значение статистики равно 22,757. Вероятность, что статистика Х 2 примет значение больше или равное 22,757 очень мала (0,000045) и может быть вычислена по формулам
=ХИ2.РАСП.ПХ(22,757;4-1)
или
=ХИ2.ТЕСТ(Observed; Expected)
Примечание : Функция ХИ2.ТЕСТ() специально создана для проверки связи между двумя категориальными переменными (см. ).
Вероятность 0,000045 существенно меньше обычного уровня значимости 0,05. Так что, у игрока есть все основания подозревать своего противника в нечестности (нулевая гипотеза о его честности отвергается).

При применении критерия Х 2 необходимо следить за тем, чтобы объем выборки n был достаточно большой, иначе будет неправомочна аппроксимация распределения статистики Х 2 . Обычно считается, что для этого достаточно, чтобы наблюденные частоты (Observed) были больше 5. Если это не так, то малые частоты объединяются в одно или присоединяются к другим частотам, причем объединенному значению приписывается суммарная вероятность и, соответственно, уменьшается число степеней свободы Х 2 -распределения .
Для того чтобы улучшить качество применения критерия Х 2 (), необходимо уменьшать интервалы разбиения (увеличивать L и, соответственно, увеличивать количество степеней свободы ), однако этому препятствует ограничение на количество попавших в каждый интервал наблюдений (д.б.>5).
Непрерывный случай
Критерий согласия Пирсона Х 2 можно применить так же в случае .
Рассмотрим некую выборку , состоящую из 200 значений. Нулевая гипотеза утверждает, что выборка сделана из .
Примечание : Cлучайные величины в файле примера на листе Непрерывное сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) . Поэтому, новые значения выборки генерируются при каждом пересчете листа.
Соответствует ли имеющийся набор данных можно визуально оценить .

Как видно из диаграммы, значения выборки довольно хорошо укладываются вдоль прямой. Однако, как и в для проверки гипотезы применим Критерий согласия Пирсона Х 2 .
Для этого разобьем диапазон изменения случайной величины на интервалы с шагом 0,5 . Вычислим наблюденные и теоретические частоты. Наблюденные частоты вычислим с помощью функции ЧАСТОТА() , а теоретические – с помощью функции НОРМ.СТ.РАСП() .
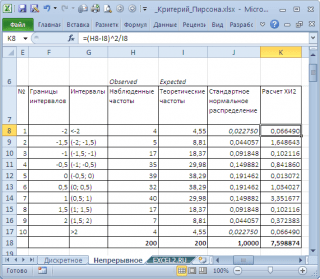
Примечание : Как и для дискретного случая , необходимо следить, чтобы выборка была достаточно большая, а в интервал попадало >5 значений.
Вычислим статистику Х 2 и сравним ее с критическим значением для заданного уровня значимости
(0,05). Т.к. мы разбили диапазон изменения случайной величины на 10 интервалов, то число степеней свободы равно 9. Критическое значение можно вычислить по формуле
=ХИ2.ОБР.ПХ(0,05;9)
или
=ХИ2.ОБР(1-0,05;9)
На диаграмме выше видно, что значение статистики равно 8,19, что существенно выше критического значения – нулевая гипотеза не отвергается.
Ниже приведена , на которой выборка приняла маловероятное значение и на основании критерия согласия Пирсона Х 2 нулевая гипотеза была отклонена (не смотря на то, что случайные значения были сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) , обеспечивающей выборку из стандартного нормального распределения ).

Нулевая гипотеза отклонена, хотя визуально данные располагаются довольно близко к прямой линии.
В качестве примера также возьмем выборку из U(-3; 3). В этом случае, даже из графика очевидно, что нулевая гипотеза должна быть отклонена.

Критерий согласия Пирсона Х 2 также подтверждает, что нулевая гипотеза должна быть отклонена.
Задача 1.
Используя критерий Пирсона, при уровне значимости a = 0,05 проверить, согласуется ли гипотеза о нормальном распределении генеральной совокупности X с эмпирическим распределением выборки объема n = 200.
Решение.
1. Вычислим  и выборочное среднее квадратическое отклонение
и выборочное среднее квадратическое отклонение ![]() .
.
2. Вычислим теоретические частоты учитывая, что n
= 200, h
= 2, = 4,695, по формуле .
.
Составим расчетную таблицу (значения функции j (x ) приведены в приложении 1).
i |
||||
3. Сравним эмпирические и теоретические частоты. Составим расчетную таблицу, из которой найдем наблюдаемое значение критерия  :
:
i |
|||||
| Сумма |
По таблице критических точек распределения (приложение 6), по уровню значимости a
= 0,05 и числу степеней свободы k
= s
– 3 = 9 – 3 = 6 находим критическую точку правосторонней критической области (0,05; 6) = 12,6.
Так как =22,2 > = 12,6, гипотезу о нормальном распределении генеральной совокупности отвергаем. Другими словами, эмпирические и теоретические частоты различаются значимо.
Задача2
Представлены статистические данные.
Результаты измерений диаметров n
= 200 валков после шлифовки обобщены в табл. (мм):
Таблица
Частотный вариационный ряд диаметров валков
| i | ||||||||
xi , мм |
||||||||
xi , мм |
||||||||
Требуется:
1) составить дискретный вариационный ряд, при необходимости упорядочив его;
2) определить основные числовые характеристики ряда;
3) дать графическое представление ряда в виде полигона (гистограммы) распределения;
4) построить теоретическую кривую нормального распределения и проверить соответствие эмпирического и теоретического распределений по критерию Пирсона. При проверке статистической гипотезы о виде распределения принять уровень значимости a = 0,05
Решение:
Основные числовые характеристики данного вариационного ряда найдем по определению. Средний диаметр валков равен (мм):
x
ср = = 6,753;
исправленная дисперсия (мм2):
D
= ![]() = 0,0009166;
= 0,0009166;
исправленное среднее квадратическое (стандартное) отклонение (мм):
s
= = 0,03028.
Рис.
Частотное распределение диаметров валков
Исходное («сырое») частотное распределение вариационного ряда, т.е. соответствие ni
(xi
), отличается довольное большим разбросом значений ni
относительно некоторой гипотетической «усредняющей» кривой (рис.). В этом случае предпочтительно построить и анализировать интервальный вариационный ряд, объединяя частоты для диаметров, попадающих в соответствующие интервалы.
Число интервальных групп K
определим по формуле Стерджесса:
K
= 1 + log2n
= 1 + 3,322lgn
,
где n
= 200 – объем выборки. В нашем случае
K
= 1 + 3,322×lg200 = 1 + 3,322×2,301 = 8,644 » 8.
Ширина интервала равна (6,83 – 6,68)/8 = 0,01875 » 0,02 мм.
Интервальный вариационный ряд представлен в табл.
Таблица Частотный интервальный вариационный ряд диаметров валков.
| k | ||||||||
xk , мм |
||||||||
Интервальный ряд может быть наглядно представлен в виде гистограммы частотного распределения.
Рис
. Частотное распределение диаметров валков. Сплошная линия – сглаживающая нормальная кривая.
Вид гистограммы позволяет сделать предположение о том, что распределение диаметров валков подчиняется нормальному закону, согласно которому теоретические частоты могут быть найдены как
nk
, теор = n
×N
(a
; s; xk
)×Dxk
,
где, в свою очередь, сглаживающая гауссова кривая нормального распределения определяется выражением:
N
(a
; s; xk
) =  .
.
В этих выражениях xk
– центры интервалов в частотном интервальном вариационном ряде.
Например, x
1 = (6,68 + 6,70)/2 = 6,69. В качестве оценок центра a
и параметра s гауссовой кривой можно принять:
a
= x
ср.
Из рис. видно, что гауссова кривая нормального распределения в целом соответствует эмпирическому интервальному распределению. Однако следует удостовериться в статистической значимости этого соответствия. Используем для проверки соответствия эмпирического распределения эмпирическому критерий согласия Пирсона c2 . Для этого следует вычислить эмпирическое значение критерия как сумму
=  ,
,
где nk
и nk
,теор – эмпирические и теоретические (нормальные) частоты, соответственно. Результаты расчетов удобно представить в табличном виде:
Таблица
Вычисления критерия Пирсона
[xk , xk+ 1), мм |
xk , мм |
nk ,теор |
||
Критическое значение критерия найдем по таблице Пирсона для уровня значимости a = 0,05 и числа степеней свободы d .f . = K – 1 – r , где K = 8 – число интервалов интервального вариационного ряда; r = 2 – число параметров теоретического распределения, оцененных на основании данных выборки (в данном случае, – параметры a и s). Таким образом, d .f . = 5. Критическое значение критерия Пирсона есть крит(a; d .f .) = 11,1. Так как c2эмп < c2крит, заключаем, что согласие между эмпирическим и теоретическим нормальным распределением является статистическим значимым. Иными словами, теоретическое нормальное распределение удовлетворительно описывает эмпирические данные.
Задача3
Коробки с шоколадом упаковываются автоматически. По схеме собственно-случайной бесповторной выборки взято 130 из 2000 упаковок, содержащихся в партии, и получены следующие данные об их весе:
Требуется используя критерий Пирсона при уровне значимости a=0,05 проверить гипотезу о том, что случайная величина X – вес упаковок – распределена по нормальному закону. Построить на одном графике гистограмму эмпирического распределения и соответствующую нормальную кривую.
Решение
1012,5
= 615,3846
Примечание:
В принципе в качестве дисперсии нормального закона распределения следует взять исправленную выборочную дисперсию. Но т.к. количество наблюдений – 130 достаточно велико, то подойдет и “обычная” .
Таким образом, теоретическое нормальное распределение имеет вид:

[xi ; xi+1 ]
Эмпирические частоты
niВероятности
pi
Теоретические частоты
npi
(ni-npi)2
Коэффициент корреляции отражает степень взаимосвязи между двумя показателями. Всегда принимает значение от -1 до 1. Если коэффициент расположился около 0, то говорят об отсутствии связи между переменными.
Если значение близко к единице (от 0,9, например), то между наблюдаемыми объектами существует сильная прямая взаимосвязь. Если коэффициент близок к другой крайней точке диапазона (-1), то между переменными имеется сильная обратная взаимосвязь. Когда значение находится где-то посередине от 0 до 1 или от 0 до -1, то речь идет о слабой связи (прямой или обратной). Такую взаимосвязь обычно не учитывают: считается, что ее нет.
Расчет коэффициента корреляции в Excel
Рассмотрим на примере способы расчета коэффициента корреляции, особенности прямой и обратной взаимосвязи между переменными.
Значения показателей x и y:
Y – независимая переменная, x – зависимая. Необходимо найти силу (сильная / слабая) и направление (прямая / обратная) связи между ними. Формула коэффициента корреляции выглядит так:

Чтобы упростить ее понимание, разобьем на несколько несложных элементов.


Между переменными определяется сильная прямая связь.
Встроенная функция КОРРЕЛ позволяет избежать сложных расчетов. Рассчитаем коэффициент парной корреляции в Excel с ее помощью. Вызываем мастер функций. Находим нужную. Аргументы функции – массив значений y и массив значений х:

Покажем значения переменных на графике:

Видна сильная связь между y и х, т.к. линии идут практически параллельно друг другу. Взаимосвязь прямая: растет y – растет х, уменьшается y – уменьшается х.
Матрица парных коэффициентов корреляции в Excel
Корреляционная матрица представляет собой таблицу, на пересечении строк и столбцов которой находятся коэффициенты корреляции между соответствующими значениями. Имеет смысл ее строить для нескольких переменных.

Матрица коэффициентов корреляции в Excel строится с помощью инструмента «Корреляция» из пакета «Анализ данных».


Между значениями y и х1 обнаружена сильная прямая взаимосвязь. Между х1 и х2 имеется сильная обратная связь. Связь со значениями в столбце х3 практически отсутствует.
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем считать взаимосвязь, или корреляцию, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность в баллах
3 столбик — неуверенность в себе в баллах
3.Затем необходимо выбрать пустую ячейку рядом с таблицей и нажать на значок f(x) в панели Excel

4.Откроется меню функций, среди категорий необходимо выбрать Статистические , а затем среди списка функций по алфавиту найти КОРРЕЛ и нажать ОК

5.Затем откроется меню аргументов функции, которое позволит выбрать нужные нам столбики с данными. Для выбора первого столбика Агрессивность нужно нажать на синюю кнопочку у строки Массив1

6.Выберем данные для Массива1 из столбика Агрессивность и нажмем на синюю кнопочку в диалоговом окне

7. Затем аналогично Массиву 1 нажмём на синюю кнопочку у строки Массив2

8.Выберем данные для Массива2 — столбик Неуверенность в себе и опять нажмем синюю кнопку, затем ОК

9.Вот, коэффициент корреляции r-Пирсона посчитан и записан в выбранной ячейке.В нашем случае он положительный и приблизительно равен 0,225 . Это говорит об умеренной положительной связи между агрессивностью и неуверенностью в себе у детей-первоклассников

Таким образом, статистическим выводом эксперимента будет: r = 0,225, выявлена умеренная положительная взаимосвязь между переменными агрессивность и неуверенность в себе.
В некоторых исследованиях требуется указывать р-уровень значимости коэффициента корреляции, однако программа Excel, в отличие от SPSS, не предоставляет такой возможности. Ничего страшного, есть (А.Д. Наследов).
Также Вы можете и приложить её к результатам исследования.

В сегодняшней статье речь пойдет о том, как переменные могут быть связаны друг с другом. С помощью корреляции мы сможем определить, существует ли связь между первой и второй переменной. Надеюсь, это занятие покажется вам не менее увлекательным, чем предыдущие!
Корреляция измеряет мощность и направление связи между x и y. На рисунке представлены различные типы корреляции в виде графиков рассеяния упорядоченных пар (x, y). По традиции переменная х размещается на горизонтальной оси, а y - на вертикальной.

График А являет собой пример положительной линейной корреляции: при увеличении х также увеличивается у, причем линейно. График В показывает нам пример отрицательной линейной корреляции, на котором при увеличении х у линейно уменьшается. На графике С мы видим отсутствие корреляции между х и у. Эти переменные никоим образом не влияют друг на друга.
Наконец, график D - это пример нелинейных отношений между переменными. По мере увеличения х у сначала уменьшается, потом меняет направление и увеличивается.
Оставшаяся часть статьи посвящена линейным взаимосвязям между зависимой и независимой переменными.
Коэффициент корреляции
Коэффициент корреляции, r, предоставляет нам как силу, так и направление связи между независимой и зависимой переменными. Значения r находятся в диапазоне между — 1.0 и + 1.0. Когда r имеет положительное значение, связь между х и у является положительной (график A на рисунке), а когда значение r отрицательно, связь также отрицательна (график В). Коэффициент корреляции, близкий к нулевому значению, свидетельствует о том, что между х и у связи не существует график С).
Сила связи между х и у определяется близостью коэффициента корреляции к - 1.0 или +- 1.0. Изучите следующий рисунок.

График A показывает идеальную положительную корреляцию между х и у при r = + 1.0. График В - идеальная отрицательная корреляция между х и у при r = — 1.0. Графики С и D - примеры более слабых связей между зависимой и независимой переменными.
Коэффициент корреляции, r, определяет, как силу, так и направление связи между зависимой и независимой переменными. Значения r находятся в диапазоне от — 1.0 (сильная отрицательная связь) до + 1.0 (сильная положительная связь). При r= 0 между переменными х и у нет никакой связи.
Мы можем вычислить фактический коэффициент корреляции с помощью следующего уравнения:

Ну и ну! Я знаю, что выглядит это уравнение как страшное нагромождение непонятных символов, но прежде чем ударяться в панику, давайте применим к нему пример с экзаменационной оценкой. Допустим, я хочу определить, существует ли связь между количеством часов, посвященных студентом изучению статистики, и финальной экзаменационной оценкой. Таблица, представленная ниже, поможет нам разбить это уравнение на несколько несложных вычислений и сделать их более управляемыми.

![]()

Как видите, между числом часов, посвященных изучению предмета, и экзаменационной оценкой существует весьма сильная положительная корреляция. Преподаватели будут весьма рады узнать об этом.
Какова выгода устанавливать связь между подобными переменными? Отличный вопрос. Если обнаруживается, что связь существует, мы можем предугадать экзаменационные результаты на основе определенного количества часов, посвященных изучению предмета. Проще говоря, чем сильнее связь, тем точнее будет наше предсказание.
Использование Excel для вычисления коэффициентов корреляции
Я уверен, что, взглянув на эти ужасные вычисления коэффициентов корреляции, вы испытаете истинную радость, узнав, что программа Excel может выполнить за вас всю эту работу с помощью функции КОРРЕЛ со следующими характеристиками:
КОРРЕЛ (массив 1; массив 2),
массив 1 = диапазон данных для первой переменной,
массив 2 = диапазон данных для второй переменной.
Например, на рисунке показана функция КОРРЕЛ, используемая при вычислении коэффициента корреляции для примера с экзаменационной оценкой.



