Шины персональных компьютеров. Стандарты системных и локальных шин - реферат
Современные вычислительные системы характеризуются:
□ стремительным ростом быстродействия микропроцессоров и некоторых внешних устройств (так, для отображения цифрового полноэкранного видео с высоким качеством необходима пропускная способность 22 Мбайт/с);
□ появлением программ, требующих выполнения большого количества интерфейсных операций (к примеру программы обработки графики в Windows, мультимедиа).
В этих условиях пропускной способности шин расширения, обслуживающих одновременно несколько устройств, оказалось недостаточно для комфортной работы пользователей, поскольку компьютеры стали подолгу ʼʼзадумыватьсяʼʼ. Разработчики интерфейсов пошли по пути создания локальных шин, подключаемых непосредственно к шине МП, работающих на тактовой частоте МП (но не на внутренней рабочей его частоте) и обеспечивающих связь с некоторыми скоростными внешними по отношению к МП устройствами: основной и внешней памятью, видеосистемами и т. д.
Сейчас существуют три базовых стандарта универсальных локальных шин: VLB, PCI и AGP.
Шина VLB (VL-bus, VESA Local Bus) представлена в 1992 году ассоциацией стандартов видеоэлектроники (VESA - торговая марка Video Electronics Standards Association) и в связи с этим часто ее называют шиной VESA. Шина VLB, по существу, является расширением внутренней шины МП для связи с видеоадаптером и реже - с жестким диском, платами мультимедиа, сетевым адаптером. Разрядность шины для данных - 32 бита͵ для адреса - 30, реальная скорость передачи данных по VLB - 80 Мбайт/с, теоретически достижимая - 132 Мбайт/с (в версии 2 - 400 Мбайт/с).
Недостатки шины VLB:
□ ориентация только на МП 80386, 80486 (не адаптирована для процессоров класса Pentium);
□ жесткая зависимость от тактовой частоты МП (каждая шина VLB рассчитана только на конкретную частоту до 33 МГц);
□ малое количество подключаемых устройств - к шине VLB может подключаться только 4 устройства;
□ отсутствует арбитраж шины - бывают конфликты между подключаемыми устройствами.
Шина PCI (Peripheral Component Interconnect, соединение внешних компонентов) - самый распространенный и универсальный интерфейс для подключения различных устройств. Разработана в 1993 году фирмой Intel. Шина PCI является намного более универсальной, чем VLB; допускает подключение до 10 устройств; имеет свой адаптер, позволяющий ей настраиваться на работу с любым МП от 80486 до современных Pentium. Тактовая частота PCI - 33 МГц, разрядность - 32 разряда для данных и 32 разряда для адреса с возможностью расширения до 64 бит, теоретическая пропускная способность 132 Мбайт/с, а в 64-битовом варианте - 264 Мбайт/с. Модификация 2.1 локальной шины PCI работает на тактовой частоте до 66 МГц и при разрядности 64 имеет пропускную способность до 528 Мбайт/с. Осуществлена поддержка режимов Plug and Play, Bus Mastering и автоконфигурирования адаптеров.
Конструктивно разъем шины на системной плате состоит из двух следующих подряд секции по 64 контакта (каждая со своим ключом). С помощью этого интерфейса к материнской плате подключаются видеокарты, звуковые карты, модемы, контроллеры SCSI и другие устройства. Как правило, на материнской плате имеется несколько разъемов PCI. Шина PCI, хотя и является локальной, выполняет и многие функции шины расширения. Шины расширения ISA, EISA, MCA (а она совместима с ними) при наличии шины PCI подключаются не непосредственно к МП (как это имеет место при использовании шины VLB), а к самой шине PCI (через интерфейс расширения). Благодаря такому решению шина является независимой от процессора (в отличие от VLB) и может работать параллельно с шиной процессора, не обращаясь к ней за запросами. Τᴀᴋᴎᴍ ᴏϬᴩᴀᴈᴏᴍ, загрузка шины процессора существенно снижается. К примеру, процессор работает с системной памятью или с кэш-памятью, а в это время по сети на жесткий диск пишется информация. Конфигурация системы с шиной PCI показана на рис. 5.8.
Шина AGP (Accelerated Graphics Port - ускоренный графический порт) - интерфейс для подключения видеоадаптера к отдельной магистрали AGP, имеющей
Глава 5. Микропроцессоры и системные платы
выход непосредственно на системную память. Разработана шина на базе стандарта PCI v2.1. Шина AGP может работать с частотой системной шины до 133 МГц и обеспечивает высочайшую скорость передачи графических данных. Ее пиковая пропускная способность в режиме четырехкратного умножения AGP4x (передаются 4 блока данных за один такт) имеет величину 1066 Мбайт/с, а в режиме восьмикратного умножения AGP8x - 2112 Мбайт/с. По сравнению с шиной PCI, в шине AGP устранена мультиплексированность линий адреса и данных (в PCI для удешевления конструкции адрес и данные передаются по одним и тем же линиям) и усилена конвейеризация операций чтения-записи, что позволяет устранить влияние задержек в модулях памяти на скорость выполнения этих операций.
Рис. 5.8. Конфигурация системы с шиной PCI
Шина AGP имеет два режима работы: DMA
и Execute.
В режиме DMA основной памятью является память видеокарты. Графические объекты хранятся в системной памяти, но перед использованием копируются в локальную память карты. Обмен ведется большими последовательными пакетами. В режиме Execute системная память и локальная память видеокарты логически равноправны. Графические объекты не копируются в локальную память, а выбираются непосредственно из системной. При этом приходится выбирать из памяти относительно малые случайно расположенные куски. Поскольку системная память выделяется динамически, блоками по 4 Кбайт, в данном режиме для обеспечения приемлемого быстродействия предусмотрен механизм, отображающий последовательные адреса фрагментов на реальные адреса 4-килобайтовых блоков в системной памяти. Эта процедура выполняется с использованием специальной таблицы (Graphic Address Re-mapping Table или GART), расположенной в памяти. Интерфейс выполнен в виде отдельного разъема, в который устанавливается AGP-видео-адаптер.
Размещено на реф.рф
Конфигурация системы с шиной AGP показана на рис. 5.9.
Внутримашинные системный и периферийный интерфейсы

Рис. 5.9. Конфигурация системы с шиной AGP
Все сказанное выше в отношении шин обобщается в табл. 5.4. Таблица 5.4. Основные характеристики шин
Локальные шины - понятие и виды. Классификация и особенности категории "Локальные шины" 2017, 2018.
С повышением тактовых частот и разрядности процессоров настала насущная проблема в повышении скорости передачи данных в шинах (какой смысл использовать камень с тактовой частотой, скажем, 66 МГц, если шина работает на частоте лишь 8,33 МГц). В одних случаях, например клавиатуре или мышке, высокая скорость ни к чему. Но инженеры фирм производителей плат расширения готовы были изготовлять устройства со скоростью, которую шины не могли предоставить.
В
ыход из создавшегося положения был найден следующий: часть операций обмена данными, требующих высоких скоростей, должна осуществляться не через стандартные разъемы шины ввода/вывода, а через дополнительные высокоскоростные интерфейсы - шину процессора, примерно так же, как подключается внешний кэш.
Дело в том, что эти самые высокоскоростные интерфейсы подключаются к шине процессора. Из этого следует, что подключаемые платы будут иметь доступ непосредственно к процессору через его шину. Такая конструкция получила название локальной шины (LB, Local Bus). Локальная шина не заменяла собой прежние стандарты, а дополняла их. Рисунок демонстрирует различие между обычной архитектурой и архитектурой с локальной шиной. Между прочим, первые шины ISA как раз и были локальными, но когда их тактовая частота превысила 8 МГц, произошло разделение.
Основными шинами в компьютере по-прежнему оставались ISA или EISA, но к ним добавлялись один или несколько слотов локальной шины. Первоначально эти слоты использовались почти исключительно для установки видеоадаптеров, при этом к 1992 году было разработано несколько несовместимых между собой вариантов локальных шин, исключительные права на которые принадлежали фирмам-изготовителям.
Такое разнообразие сдерживала распространение локальных шин, поэтому Ассоциация по стандартам в области видеоэлектроники VESA (Video Electronic Standard Association), представляющая более 100 компаний, предложила в августе 1992 года свою спецификацию локальной шины VESA Local Bus (VL-bus или VLB) , которая не изменяла, а дополняла существующие стандарты. Шина VLB разработана с целью увеличить пропускную способность между основным процессором и видеокартой, для этого просто к основным шинам добавлялось несколько новых быстродействующих локальных слотов. Основная функция, для которой была предназначена новая шина, – обмен данными с видеоадаптером.
Представляла собой 32-битную шину, которая использовала третий и четвёртый разъём в виде продолжения обычного слота ISA. Шина работала на номинальной частоте 33 МГц и обеспечивала существенный прирост производительности по сравнению с ISA. В дальнейшем шину VLB стали использовать производители контроллеров жестких дисков и других устройств, требующих высокоскоростной передачи данных. Выпускались даже 100-мегабитные Ethernet контроллеры с шиной VLB. Широкое распространение шины VESA обусловила ее относительная дешевизна и совместимость “сверху вниз” со своей предшественницей – шиной ISA. Разъем VLB есть разъем ISA с “продолжением”.
Основные характеристики VL-bus таковы:
поддержка процессоров серий 80386 и 80486. Шина разработана для использования в однопроцессорных системах, при этом в спецификации предусмотрена возможность поддержки х86-несовместимых процессоров с помощью моста (bridge chip);
максимальное число bus master - 3 (не включая контроллер шины). При необходимости возможна установка нескольких подсистем для поддержки большего числа master. Несмотря на то что изначально шина была разработана для поддержки видеоконтроллеров, возможна поддержка и других устройств (например, контроллеров жесткого диска);
допускается работа шины на частоте до 66 МГц, однако электрические характеристики разъема VL-bus ограничивают ее до 50 МГц (это ограничение, естественно, не относится к интегрированным в материнскую плату устройствам);
двунаправленная (bi-directional) 32-разрядная шина данных поддерживает и 16-разрядный обмен. В спецификацию заложена возможность 64-разрядного обмена;
поддержка DMA обеспечивается только для bus masters. Шина не поддерживает специальных "инициаторов" DMA;
максимальная теоретическая пропускная способность шины 160 Мб/с (при частоте шины 50 МГц), стандартная - 107 Мб/с при частоте 33 МГц;
поддержка пакетного режима обмена (для материнских плат 80486, поддерживающих этот режим). Пять линий используется для идентификации типа и скорости процессора, сигнал Burst Last (BLAST#) используется для активизации этого режима. Для систем, не поддерживающих этот режим, линия устанавливается в 0;
использование 58-контактного разъема МСА. Максимально поддерживается 3 слота (на некоторых 50-мегагерцовых шинах возможна установка только 1 слота). Слот VL-bus устанавливается в линию за слотами ISA/EISA/MCA, поэтому VL-платам доступны все линии этих шин;
поддержка, как интегрированного кэш- процессора, так и кэша на материнской плате. Напряжение питания - 5 В. Устройства с уровнем выходного сигнала 3,3 В поддерживаются при условии, что они могут работать с уровнем входного сигнала 5 В.
Эта 32/32-разрядная шина разрабатывалась для машин с 386, 486 и Pentium процессорами. Наиболее широкое распространение шина VLB получила на материнских платах 486. На них VESA – это линии адреса, данных и управления процессора, выведенные на разъем. Это обстоятельство накладывает значительные ограничения на VLB- карты расширения – временные и нагрузочные параметры должны быть четко выдержаны. Как указано в инструкциях на многие материнские платы, число VLB- карт при тактовой частоте 25 МГц не должно превышать трех, при 33 МГц – двух, при 40 и 50 МГц – одной. В случае нарушения этих требований система будет работать нестабильно, поскольку превышена нагрузочная способность процессора.
Для оценки скорости шины можно привести следующий расчет: если карта расширения работает на частоте 50 МГц, тогда пропускная способность шины будет равна 32*50*10 6 = 1,6*10 9 Мбит/с = 200 Мбайт/с, что довольно много. Однако не следует забывать, что такая скорость почти никогда не может быть востребована, поскольку данные из видеопамяти не могут читаться с такой скоростью. Кроме того, во время обращения к VLB- карте процессор не может больше заниматься ничем, сколько бы медленным не было устройство на этой карте (например, последовательный порт).
Шина VL-bus явилась огромным шагом вперед по сравнению с ISA как по производительности, так и по дизайну. Одним из преимуществ шины являлось то, что она позволяла создавать карты, работающие с существующими чипсетами и не содержащие большого количества схем дорогостоящей управляющей логики. В результате VL-карты получались дешевле аналогичных EISA-карт. Однако и эта шина не была лишена недостатков, главными из которых являлись следующие:
ориентация на 486-й процессор. VL-bus жестко привязана к шине процессора 80486, которая отличается от шин Pentium и Pentium Pro /Pentium II.
ограниченное быстродействие. Как уже было сказано, реальная частота VL-bus - не больше 50 МГц. Причем при использовании процессоров с множителем частоты шина использует основную частоту (так, для 486DX2-66 частота шины будет 33 МГц);
схемотехнические ограничения. К качеству сигналов, передаваемых по шине процессора, предъявляются очень жесткие требования, соблюсти которые можно только при определенных параметрах нагрузки каждой линии шины. По мнению Intel, установка недостаточно аккуратно разработанных VL-плат может привести не только к потерям данных и нарушениям синхронизации, но и к повреждению системы;
ограничение количества плат. Это ограничение вытекает также из необходимости соблюдения ограничений на нагрузку каждой линии.
Популярность шины VLB продлилась до 1994 года. Главная особенность шины, которая позволяла достичь высокой производительности, послужила и причиной ухода VLB с рынка. Шина являлась прямым расширением шины 486 процессора/памяти, работающим на той же скорости, что и процессор (отсюда и имя - локальная шина - local bus). Прямое соединение означает, что подключение слишком большого числа устройств приводило к опасности создания помех самому процессору, особенно если сигналы проходили через слот. VESA рекомендовала использовать не более двух слотов на тактовых частотах 33 МГц или трёх слотов, если они использовали специальный буфер. На более высоких тактовых частотах следовало подключать не более двух устройств, а на частоте 50 МГц оба устройства VLB должны быть встроены в материнскую плату.
Поскольку шина VLB работает синхронно с процессором, увеличение частоты процессора приводило к появлению проблем с периферией VLB. Чем быстрее должна была работать периферия, тем она дороже стоила по причине трудностей, связанных с производством высокоскоростных компонент. Лишь немногие устройства VLB поддерживали скорость выше 40 МГц.
Современные вычислительные системы характеризуются:
□ стремительным ростом быстродействия микропроцессоров и некоторых внешних устройств (так, для отображения цифрового полноэкранного видео с высоким качеством необходима пропускная способность 22 Мбайт/с);
□ появлением программ, требующих выполнения большого количества интерфейсных операций (например программы обработки графики в Windows, мультимедиа).
В этих условиях пропускной способности шин расширения, обслуживающих одновременно несколько устройств, оказалось недостаточно для комфортной работы пользователей, поскольку компьютеры стали подолгу «задумываться». Разработчики интерфейсов пошли по пути создания локальных шин, подключаемых непосредственно к шине МП, работающих на тактовой частоте МП (но не на внутренней рабочей его частоте) и обеспечивающих связь с некоторыми скоростными внешними по отношению к МП устройствами: основной и внешней памятью, видеосистемами и т. д.
Сейчас существуют три основных стандарта универсальных локальных шин: VLB, PCI и AGP.
Шина VLB (VL-bus, VESA Local Bus) представлена в 1992 году ассоциацией стандартов видеоэлектроники (VESA - торговая марка Video Electronics Standards Association) и поэтому часто ее называют шиной VESA. Шина VLB, по существу, является расширением внутренней шины МП для связи с видеоадаптером и реже - с жестким диском, платами мультимедиа, сетевым адаптером. Разрядность шины для данных - 32 бита, для адреса - 30, реальная скорость передачи данных по VLB - 80 Мбайт/с, теоретически достижимая - 132 Мбайт/с (в версии 2 - 400 Мбайт/с).
Недостатки шины VLB:
□ ориентация только на МП 80386, 80486 (не адаптирована для процессоров класса Pentium);
□ жесткая зависимость от тактовой частоты МП (каждая шина VLB рассчитана только на конкретную частоту до 33 МГц);
□ малое количество подключаемых устройств - к шине VLB может подключаться только 4 устройства;
□ отсутствует арбитраж шины - могут быть конфликты между подключаемыми устройствами.
Шина PCI (Peripheral Component Interconnect, соединение внешних компонентов) - самый распространенный и универсальный интерфейс для подключения различных устройств. Разработана в 1993 году фирмой Intel. Шина PCI является намного более универсальной, чем VLB; допускает подключение до 10 устройств; имеет свой адаптер, позволяющий ей настраиваться на работу с любым МП от 80486 до современных Pentium. Тактовая частота PCI - 33 МГц, разрядность - 32 разряда для данных и 32 разряда для адреса с возможностью расширения до 64 бит, теоретическая пропускная способность 132 Мбайт/с, а в 64-битовом варианте - 264 Мбайт/с. Модификация 2.1 локальной шины PCI работает на тактовой частоте до 66 МГц и при разрядности 64 имеет пропускную способность до 528 Мбайт/с. Осуществлена поддержка режимов Plug and Play, Bus Mastering и автоконфигурирования адаптеров.
Конструктивно разъем шины на системной плате состоит из двух следующих подряд секции по 64 контакта (каждая со своим ключом). С помощью этого интерфейса к материнской плате подключаются видеокарты, звуковые карты, модемы, контроллеры SCSI и другие устройства. Как правило, на материнской плате имеется несколько разъемов PCI. Шина PCI, хотя и является локальной, выполняет и многие функции шины расширения. Шины расширения ISA, EISA, MCA (а она совместима с ними) при наличии шины PCI подключаются не непосредственно к МП (как это имеет место при использовании шины VLB), а к самой шине PCI (через интерфейс расширения). Благодаря такому решению шина является независимой от процессора (в отличие от VLB) и может работать параллельно с шиной процессора, не обращаясь к ней за запросами. Таким образом, загрузка шины процессора существенно снижается. Например, процессор работает с системной памятью или с кэш-памятью, а в это время по сети на жесткий диск пишется информация. Конфигурация системы с шиной PCI показана на рис. 5.8.
Шина AGP (Accelerated Graphics Port - ускоренный графический порт) - интерфейс для подключения видеоадаптера к отдельной магистрали AGP, имеющей
Глава 5. Микропроцессоры и системные платы
выход непосредственно на системную память. Разработана шина на основе стандарта PCI v2.1. Шина AGP может работать с частотой системной шины до 133 МГц и обеспечивает высочайшую скорость передачи графических данных. Ее пиковая пропускная способность в режиме четырехкратного умножения AGP4x (передаются 4 блока данных за один такт) имеет величину 1066 Мбайт/с, а в режиме восьмикратного умножения AGP8x - 2112 Мбайт/с. По сравнению с шиной PCI, в шине AGP устранена мультиплексированность линий адреса и данных (в PCI для удешевления конструкции адрес и данные передаются по одним и тем же линиям) и усилена конвейеризация операций чтения-записи, что позволяет устранить влияние задержек в модулях памяти на скорость выполнения этих операций.
Рис. 5.8. Конфигурация системы с шиной PCI
Шина AGP имеет два режима работы: DMA и Execute. В режиме DMA основной памятью является память видеокарты. Графические объекты хранятся в системной памяти, но перед использованием копируются в локальную память карты. Обмен ведется большими последовательными пакетами. В режиме Execute системная память и локальная память видеокарты логически равноправны. Графические объекты не копируются в локальную память, а выбираются непосредственно из системной. При этом приходится выбирать из памяти относительно малые случайно расположенные куски. Поскольку системная память выделяется динамически, блоками по 4 Кбайт, в этом режиме для обеспечения приемлемого быстродействия предусмотрен механизм, отображающий последовательные адреса фрагментов на реальные адреса 4-килобайтовых блоков в системной памяти. Эта процедура выполняется с использованием специальной таблицы (Graphic Address Re-mapping Table или GART), расположенной в памяти. Интерфейс выполнен в виде отдельного разъема, в который устанавливается AGP-видео-адаптер. Конфигурация системы с шиной AGP показана на рис. 5.9.
Внутримашинные системный и периферийный интерфейсы

Рис. 5.9. Конфигурация системы с шиной AGP
Все сказанное выше в отношении шин обобщается в табл. 5.4. Таблица 5.4. Основные характеристики шин
Локальная шина (Local bus)
Все описанные ранее шины имеют общий недостаток — сравнительно низкую пропускную способность. Это связано с тем, что шины разрабатывались в расчете на медленные процессоры. В дальнейшем быстродействие процессора возрастало, а характеристики шин улучшались в основном "экстенсивно", за счет добавления новых линий. Препятствием для повышения частоты шины являлось огромное количество выпущенных плат, которые не могли работать на больших скоростях обмена (МСА это касается в меньшей степени, но в силу вышеизложенных причин эта архитектура не играла заметной роли на рынке). В то же время в начале 90-х годов в мире персональных компьютеров произошли изменения, потребовавшие резкого увеличения скорости обмена с устройствами:
- создание нового поколения процессоров типа Intel 80486, работающих на частотах до 66 MHz;
- увеличение емкости жестких дисков и создание более быстрых контроллеров;
- разработка и активное продвижение на рынок графических интерфейсов пользователя (типа Windows или OS/2) привели к созданию новых графических адаптеров, поддерживающих более высокое разрешение и большее количество цветов (VGA и SVGA).
Очевидным выходом из создавшегося положения является следующий: осуществлять часть операций обмена данными, требующих высоких скоростей, не через шину ввода/вывода, а через шину процессора, примерно так же, как подключается внешний кэш. Такая конструкция получила название локальной шины (Local Bus). Рисунки наглядно демонстрируют различие между обычной архитектурой и архитектурой с локальной шиной.
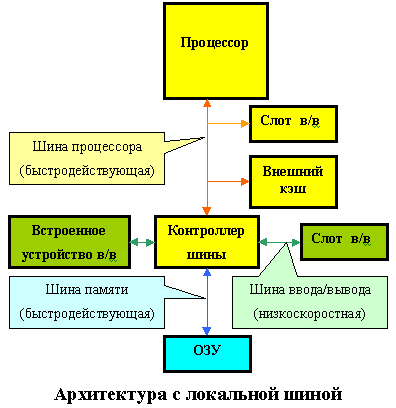
Локальная шина не заменяла собой прежние стандарты, а дополняла их. Основными шинами в компьютере по-прежнему оставались ISA или EISA, но к ним добавлялись один или несколько слотов локальной шины. Первоначально эти слоты использовались почти исключительно для установки видеоадаптеров, при этом к 1992 году было разработано несколько несовместимых между собой вариантов локальных шин, исключительные права на которые принадлежали фирмам-изготовителям. Естественно, такая неразбериха сдерживала распространение локальных шин, поэтому VESA (Video Electronic Standard Association) — ассоциация, представляющая более 100 компаний — предложила в августе 1992 года свою спецификацию локальной шины.
Локальная шина VESA (VL-bus)
Основные характеристики VL-bus таковы.
- Поддержка процессоров серий 80386 и 80486. Шина разработана для использования в однопроцессорных системах, при этом в спецификации предусмотрена возможность поддержки х86-несовместимых процессоров с помощью моста (bridge chip).
- Максимально число bus master — 3 (не включая контроллер шины). При необходимости возможна установка нескольких подсистем для поддержки большего числа masterов.
- Несмотря на то, что изначально шина была разработана для поддержки видеоконтроллеров, возможна поддержка и других устройств (например, контроллеров жесткого диска).
- Стандарт допускает работу шины на частоте до 66 MHz, однако электрические характеристики разъема VL-bus ограничивают ее до 50 MHz (это ограничение, естественно, не относится к интегрированным в материнскую плату устройствам).
- Двунаправленная (bi-directional) 32-разрядная шина данных поддерживает и 16-разрядный обмен. В спецификацию заложена возможность 64-разрядного обмена.
- Поддержка DMA обеспечивается только для bus masters. Шина не поддерживает специальных "инициаторов" DMA.
- Максимальная теоретическая пропускная способность шины — 160 МВ/сек (при частоте шины 50 MHz), стандартная — 107 МВ/сек при частоте 33 MHz.
- Поддерживается пакетный режим обмена (для материнских плат 80486, поддерживающих этот режим). 5 линий используется для идентификации типа и скорости процессора, сигнал Burst Last (BLAST#) используется для активизации этого режима. Для систем, не поддерживающих этот режим, линия устанавливается в 0.
- Шина использует 58-контактный разъем МСА. Максимально поддерживается 3 слота (на некоторых 50-мегагерцовых шинах возможна установка только 1 слота).
- Слот VL-bus устанавливается в линию за слотами ISA/EISA/MCA, поэтому VL-платам доступны все линии этих шин.
- Поддерживается как интегрированный кэш процессора, так и кэш на материнской плате.
- Напряжение питания — 5 В. Устройства с уровнем выходного сигнала 3.3 В поддерживаются при условии, что они могут работать с уровнем входного сигнала 5 В.
Шина VL-bus явилась огромным шагом вперед по сравнению с ISA как по производительности, так и по дизайну. Одним из преимуществ шины являлось то, что она позволяла создавать карты, работающие с существующими чипсетами и не содержащие большого количества схем дорогостоящей управляющей логики. В результате VL-карты получались дешевле аналогичных EISA-карт. Однако и эта шина не была лишена недостатков, главными из которых являлись следующие.
- Ориентация на 486-ой процессор. VL-bus жестко привязана к шине процессора 80486, которая отличается от шин Pentium и Pentium Pro/Pentium II.
- Ограниченное быстродействие. Как уже было сказано, реальная частота VL-bus — не больше 50 MHz. Причем при использовании процессоров с множителем частоты шина использует основную частоту (так, для 486DX2-66 частота шины будет 33 MHz).
- Схемотехнические ограничения. К качеству сигналов, передаваемых по шине процессора, предъявляются очень жесткие требования, соблюсти которые можно только при определенных параметрах нагрузки каждой линии шины. По мнению Intel, установка недостаточно аккуратно разработанных VL-плат может привести не только к потерям данных и нарушениям синхронизации, но и к повреждению системы.
- Ограничение количества плат. Это ограничение вытекает также из необходимости соблюдения ограничений на нагрузку каждой линии.
Несмотря на существующие недостатки, VL-bus была несомненным лидером на рынке, так как позволяла устранить узкое место сразу в двух подсистемах — видеоподсистеме и подсистеме обмена с жестким диском. Однако лидерство было недолгим, поскольку корпорация Intel разработала свою новинку — шину PCI. По мнению компании, VL-bus базировалась на технологиях 11-летней давности и являлась всего лишь "заплаткой", компромиссом между производителями. Правда, VESA заявляла, что обе шины могут "уживаться" совместно в одной системе. Intel соглашалась, что такое соседство возможно, но задавала встречный убийственный вопрос: "А зачем?". Справедливости ради, надо сказать, что PCI действительно была избавлена от большинства недостатков, присущих VL-bus.
ВВЕДЕНИЕ
Шина – это канал пересылки данных, используемый совместно различными блоками системы. Шина может представлять собой набор проводящих линий, вытравленных на печатной плате, провода, припаянные к выводам разъемов, в которые вставляются печатные платы, либо плоский кабель. Компоненты компьютерной системы физически расположены на одной или нескольких печатных платах, причем их число и функции зависят от конфигурации системы, её изготовителя, а часто и от поколения микропроцессора.
Основными характеристиками шин являются разрядность передаваемых данных и скорость передачи данных.
Наибольший интерес вызывают два типа шин – системный и локальный.
Системная шина предназначена для обеспечения передачи данных между периферийными устройствами и центральным процессором, а также оперативной памятью.
Локальной шиной, как правило, называется шина, непосредственно подключенная к контактам микропроцессора, т.е. шина процессора.
1. СИСТЕМНЫЕ ШИНЫ
Основной обязанностью системной шины является передача информации между базовым микропроцессором и остальными электронными компонентами компьютера. По этой шине осуществляется также адресация устройств и происходит обмен специальными служебными сигналами. Таким образом, упрощенно системную шину можно представить как совокупность сигнальных линий, объединенных по их назначению (данные, адреса, управление). Передачей информации по шине управляет одно из подключенных к ней устройств или специально выделенный для этого узел, называемый арбитром шины.
Системная шина IBM PC и IBM PC/XT была предназначена для одновременной передачи только 8 бит информации, так как используемый в компьютерах микропроцессор 18088 имел 8 линий данных. Кроме того, системная шина включала 20 адресных линий, которые ограничивали адресное пространство пределом в 1 Мбайт. Для работы с внешними устройствами в этой шине были предусмотрены также 4 линии аппаратных прерываний (IRQ) и 4 линии для требования внешними устройствами прямого доступа в память (DMA, Direct Memory Access). Для подключения плат расширения использовались специальные 62-контактные разъемы. Заметим, что системная шина и микропроцессор синхронизировались от одного тактового генератора с частотой 4,77 МГц. Таким образом, теоретически скорость передачи данных могла достигать более 4,5 Мбайта/с.
1.1 Шина ISA
Шина ISA (Industry Standart Architecture) – шина, применявшаяся с первых моделей PC и ставшая промышленным стандартом. В PC моделей XT применялась шина с разрядностью данных 8 бит и адреса – 20 бит. В моделях AT шина была расширена до 16 бит данных и 24 бита адреса, какой она остается до сих пор. Конструктивно шина выполнена в виде двух слотов. Подмножество ISA-8 использует только первый 62-контактный слот, в ISA-16 применяется дополнительный 36-контактный слот. Тактовая частота – 8 МГц. Скорость передачи данных до 16 Мбайт\с. Обладает хорошей помехоустойчивостью.
Шина обеспечивает своим абонентам возможность отображения 8- или 16-битных регистров на пространство ввода-вывода и памяти. Диапазон доступных адресов памяти ограничен областью UMA (U nified M emory A rchitecture - унифицированная архитектура памяти), но для шины ISA-16 специальными опциями BIOS Setup может быть разрешено и пространство в области между15-м и 16-м мегабайтом памяти (правда при этом компьютер не сможет использовать более 15 Мбайт ОЗУ). Диапазон адресов ввода-вывода сверху ограничен количеством используемых для дешифрации бит адреса, нижняя граница ограничена областью адресов 0-FFh, зарезервированных под устройства систнемной платы. В PC была принята 10-битная адресация ввода-вывода, при которой линии адреса A устройствами игнорировались. Таким образом, диапазон адресов устройств шины ISA ограничивается областью 100h-3FFh, то есть всего 758 адресов 8-битных регистров. На некоторые области этих адресов претендуют и системные устройства. Впоследствии стали применять и 12-битную адресацию (диапазон 100h-FFFh), но при ее использовании всегда необходимо учитывать возможность присутствия на шине и старых 10-битных адаптеров, которые "отзовутся" на адрес с подходящими ему битами A во всей допустимой области четыре раза.
В распоряжении абонентов шины ISA-8 может быть до 6 линий запросов прерываний IRQ (Interrupt Request), для ISA-16 их число достигает 11. Заметим, что при конфигурировании BIOS Setup часть из этих запросов могут отобрать устройства системной платы или шина PCI.
Абоненты шины могут использовать до трех 8-битных каналов DMA (D irect M emory A ccess - прямой доступ к памяти), а на 16-битной шине могут быть доступными еще три 16-битных канала. Сигналы 16-битных каналов могут использоваться и для получения прямого управления шиной устройством Bus-Master. При этом канал DMA используется для обеспечения арбитража управления шиной, а адаптер Bus-Master формирует все адресные и управляющие сигналы шины, не забывая "отдать" управление шиной процессору не более, чем через 15 микросекунд (чтобы не нарушить регенерацию памяти).
Все перечисленные ресурсы системной шины должны быть бесконфликтно распределены между абонентами. Бесконфликтность подразумевает следующее:
Каждый абонент должен при операциях чтения управлять шиной данных (выдавать информацию) только по своим адресам или по обращению к используемому им каналу DMA. Области адресов для чтения не должны пересекаться. "Подсматривать" не ему адресованные операции записи не возбраняется.
Назначенную линию запроса прерывания IRQx абонент должен держать на низком уровне в пассивном состоянии и переводить в высокий уровень для активации запроса. Неиспользуемыми линиями запросов абонент управлять не имеет права, они должны быть электрически откоммутированы или подключаться к буферу, находящемуся в третьем состоянии. Одной линией запроса может пользоваться только одно устройство. Такая нелепость (с точки зрения схемотехники ТТЛ) была допущена в первых PC и в жертву совместимости старательно тиражируется уже много лет.
Задача распределения ресурсов в старых адаптерах решалась с помощью джамперов, затем появились программно-конфигурируемые устройства, которые практически вытеснены автоматически конфигурируемыми платами PnP.
Для шин ISA ряд фирм выпускает карты-прототипы (Protitype Card), представляющие собой печатные платы полного или уменьшенного формата с крепежной скобой. На платах установлены обязательные интерфейсные цепи - буфер данных, дешифратор адреса и некоторые другие. Остальное поле платы представляет собой "слепыш", на котором разработчик может разместить макетный вариант своего устройства. Эти платы удобны для макетной проверки нового изделия, а также для монтажа единичных экземпляров устройства, когда разработка и изготовление печатной платы нерентабельно.
С появлением 32-битных процессоров делались попытки расширения разрядности шины, но все 32-битные шины ISA не являются стандартизованными, кроме шины EISA.
1.2 Шина EISA
С появлением 32-разрядных микропроцессоров 80386 (версия DX) фирмами Compaq, NEC и рядом других фирм, была создана 32-разрядная шина EISA, полностью совместимая с ISA.
Шина EISA (Extended ISA) - жестко стандартизованное расширение ISA до 32 бит. Конструктивное исполнение обеспечивает совместимость с ней и обычных ISA-адаптеров. Узкие дополнительные контакты расширения расположены между ламелями разъема ISA и ниже таким образом, что адаптер ISA, не имеющий дополнительных ключевых прорезей в краевом разъеме, не достает до них. Установка карт EISA в слоты ISA недопустима, поскольку ее специфические цепи попадут на контакты цепей ISA, в результате чего системная плата окажется неработоспособной.
Расширение шины касается не только увеличения разрядности данных и адреса: для режимов EISA используются дополнительные управляющие сигналы, обеспечивающие возможность применения более эффективных режимов передачи. В обычном (не пакетном) режиме передачи за каждую пару тактов может быть передано до 32 бит данных (один такт на фазу адреса, один - на фазу данных). Максимальную производительность шины реализует пакетный режим (Burst Mode) – скоростной режим пересылки пакетов данных без указания текущего адреса внутри пакета. Внутри пакета очередные данные могут передаваться в каждом такте шины, длина пакета может достигать 1024 байт. Шина предусматривает и более производительные режимы DMA, при которых скорость обмена может достигать 33 Мбайт/с. Линии запросов прерываний допускают разделяемое использование, причем сохраняется и совместимость с ISA-картами: каждая линия запроса может программироваться на чувствительность как по перепаду, как в ISA, так и по низкому уровню. Шина допускает потребление каждой картой расширения мощности до 45 Вт, но полную мощность, как правило не потребляет ни один адаптер.
Каждый слот (максимум - 8) и системная плата могут иметь селективное разрешение адресации ввода-вывода и отдельные линии запроса и подтверждения управления шиной. Арбитраж запросов выполняет устройство ISP (Integrated System Peripheral). Обязательной принадлежностью системной платы с шиной EISA является энергонезависимая память конфигурации NVRAM, в которой хранится информация об устройствах EISA для каждого слота. Формат записей стандартизован, для модификации конфигурационной информации применяется специальная утилита ECU (EISA Configuration Utility). Архитектура позволяет при использовании программно-конфигурируемых адаптеров автоматически разрешать конфликты использования системных ресурсов программным путем, но в отличие от спецификации PnP, EISA не допускает динамического реконфигурирования. Все изменения конфигурации возможны только в режиме конфигурирования, после выхода из которого необходима перезагрузка компьютера. Изолированный доступ к портам ввода-вывода каждой карты во время конфигурирования обеспечивает просто: сигнал AEN, разрешающий декодирования адреса в цикле ввода-вывода, на каждый слот приходит по отдельной линии AENx, в это время программно-управляемой. Таким образом можно по отдельности обращаться и к обычным картам ISA, но из это бесполезно, поскольку карты ISA не поддерживают обмена конфигурационной информацией, предусмотренного шиной EISA. На некоторых идеях конфигурирования EISA выросла спецификация PnP для шины ISA (формат конфигурационных записей ESCD во многом напоминает NVRAM EISA).
EISA - дорогая, но оправдывающая себя архитектура, применяющаяся в многозадачных системах, на файл-серверах и везде, где требуется высокоэффективное расширение шины ввода-вывода.
1.3 Шина MCA
Шина MCA (MicroChannel Architecture) - микроканальная архитектура - была введена в пику конкурентам фирмой IBM для своих компьютеров PS/2 начиная с модели 50 в 1987 году. Обеспечивает быстрый обмен данными между отдельными устройствами, в частности с оперативной памятью. Шина MCA абсолютно несовместима с ISA/EISA и другими адаптерами. Состав управляющих сигналов, протокол и архитектура ориентированы на асинхронное функционирование шины и процессора, что снимает проблемы согласования скоростей процессора и периферийных устройств. Адаптеры MCA широко используют Bus-Mastering, все запросы идут через устройство CACP (Central Arbitration Control Point). Архитектура позволяет эффективно и автоматически конфигурировать все устройства программным путем (в MCA PS/2 нет ни одного переключателя).
При всей прогрессивности архитектуры (относительно ISA) шина MCA не пользуется популярностью из-за узости круга производителей MCA-устройств и полной их несовместимости с массовыми ISA-системами. Однако MCA еще находит применение в мощных файл-серверах, где требуется обеспечение высоконадежного производительного ввода-вывода.
2. ЛОКАЛЬНЫЕ ШИНЫ
Разработчики компьютеров, системные платы которых основывались на микропроцессорах 180386/486, стали использовать раздельные шины для памяти и устройств ввода-вывода, что позволило максимально задействовать возможности оперативной памяти, так как именно в данном случае память может работать с наивысшей для нее скоростью. Тем не менее, при таком подходе вся система не может обеспечить достаточной производительности, так как устройства, подключенные через разъемы расширения, не могут достичь скорости обмена, сравнимой с процессором. В основном это касается работы с контроллерами накопителей и видеоадаптерами. Для решения возникшей проблемы стали использовать так называемые локальные (local) шины, которые непосредственно связывают процессор с контроллерами периферийных устройств.
Первые IBM PC-совместимые компьютеры с локальными шинами не были, естественно, стандартизованы. Одним из ведущих изготовителей персональных компьютеров, впервые реализовавшим видеоподсистему с локальной шиной, была компанияNECTechnologies. Еще в 1991 году эта фирма представила свою оригинальную разработку Image Video.
В последнее время появились две локальные шины, признанные промышленными: шина VLB, предложенная ассоциацией VESA (Video Electronics Standards Association), и PCI (Peripheral Component Interconnect), разработанная фирмой Intel. Обе эти шины предназначены, вообще говоря, для одного и того же - для увеличения быстродействия компьютера, позволяя таким периферийным устройствам, как видеоадаптеры и контроллеры накопителей, работать с тактовой частотой до 33 МГц и выше. Обе шины используют разъемы типа МСА. На этом, впрочем, их сходство и заканчивается, поскольку требуемая цель достигается разными средствами.
Если VL-bus является, по сути, расширением шины процессора (вспомним шину IBM PC/XT), то PCI по своей организации более тяготеет к системным шинам, например к EISA, и представляет собой абсолютно новую разработку. Строго говоря, PCI относится к классу так называемых mezzanine-шин, то есть шин-"пристроек", поскольку между локальной шиной процессора и самой PCI находится специальная микросхема согласующего "моста" (bridge).
2.1 Шина VLB
Локальная шина стандарта VLB (VESA Local Bus, VESA – Video Equipment Standart Association – Ассоциация стандартов видеооборудования) разработана в 1992 году. Главным недостатком шины VLB является невозможность её использования с процессорами, пришедшими на замену МП 80486 или существующими параллельно с ним (Alpha, PowerPC и др.).
Шины ввода-вывода ISA, MCA, EISA имеют низкую производительность, обусловленную их местом в структуре PC. Современные приложения (особенно графические) требуют существенного повышения пропускной способности, которое могут обеспечить современные процессоры. Одним из решений проблемы повышения пропускной способности было применение в качестве шины подключения периферийных устройств локальной шины процессора 80486. Шину процессора использовали как место подключения встроенной периферии системной платы (контроллер дисков, графического адаптера).
VLB - стандартизованная 32-битная локальная шина, практически представляющая собой сигналы системной шины процессора 486, выведенные на дополнительные разъемы системной платы. Шина сильно ориентирована на 486 процессор, хотя возможно ее использование и с процессорами класса 386. Для процессоров Pentium была принята спецификация 2.0, в которой разрядность шины данных увеличена до 64, но она распространения не получила. Аппаратные преобразователи шины новых процессоров в шину VLB, будучи искусственными "наростами" на шиннной архитектуре, не прижились, и VLB дальнейшего развития не получила.
Конструктивно VLB-слот аналогичен 16-битному обычному MCA-слоту, но является расширением системного слота шины ISA-16, EISA или MCA, располагаясь позади него вблизи от процессора. Из-за ограниченной нагрузочной способности шины процессора больше трех слотов VLB на системной плате не устанавливают. Максимальная тактовая частота шины - 66 МГц, хотя надежнее шина работает на частоте 33 МГц. При этом декларируется пиковая пропускная способность 132 Мбайт/с (33 МГц x 4 байта), но она достигается только внутри пакетного цикла во время передач данных. Реально в пакетном цикле передача 4 x 4 = 16 байт данных требует 5 тактов шины, так что даже в пакетном режиме пропускная способность составляет 105.6 Мбайт/с, а в обычном режиме (такт на фазу адреса и такт на фазу данных) - всего 66 Мбайт/с, хотя это и значительно больше, чем у ISA. Жесткие требования к временным характеристикам процессорной шины при большой нагрузке (в т. ч. и микросхемами внешнего кэша) могут привести к неустойчивой работе: все три VLB-слота могут использоваться только на частоте 40 МГц, при нагруженной системной плате на 50 МГц может работать только один слот. Шина в принципе допускает и применение активных (Bus-Master) адаптеров, но арбитраж запросов возлагается на сами адаптеры. Обычно шина допускает установку не более двух Bus-Master адаптеров, один из которых устанавливается в "Master"-слот.
Шину VLB обычно использовали для подключения графического адаптера и контроллера дисков. Адаптеры локальных сетей для VLB практически не встречаются. Иногда встречаются системные платы, у которых в описании указано, что они имеют встроенный графический и дисковый адаптер с шиной VLB, но самих слотов VLB нет. Это означает, что на плате установлены микросхемы указанных адаптеров, предназначенные для подключения к шине VLB. Такая неявная шина по производительности, естественно, не уступает шине с явными слотами. С точки зрения надежности и совместимости это даже лучше, поскольку проблемы совместимости карт и системных плат для шины VLB стоят особенно остро.
2.2 Шина PCI
Шина PCI (Peripheral Component Interconnect bus – взаимосвязь периферийных компонентов) - шина соединения периферийных компонентов. Была анонсирована компанией Intel в июне 1992 года на выставке PC Expo.
Эта шина занимает особое место в современной PC-архитектуре (mezzanine bus), являясь мостом между локальной шиной процессора и шиной ввода-вывода ISA/EISA или MCA. Эта шина разрабатывалась в расчете на Pentium-системы, но хорошо сочетается и с 486 процессорами, а также с не-Intel"овскими процессорами. Шина PCI является четко стандартизованной высокопроизводительной шиной расширения ввода-вывода. PCI – мультиплексная 32-разрядная шина. Существует также 64-разрядная версия. Частота шины 20-33 МГц. Стандарт PCI 2.1 допускает и частоту 66 МГц. Теоретическая максимальная скорость 132/264 Mбайт/с для 32/64 бит при 33 МГц, и 528 Мбайт/с при 66 МГц. Слот PCI достаточен для подключения адаптера (в отличие от VLB), на системной плате он может сосуществовать с любой из шин ввода-вывода и даже с VLB (хотя в этом и нет необходимости).
На одной шине PCI может быть не более четырех устройств (слотов). Мост шины PCI (PCI Bridge) - это аппаратные средства подключения шины PCI к другим шинам. Host Bridge - главный мост - используется для подключения PCI к системной шине (шине процессора или процессоров). Peer-to-Peer Bridge - одноранговый мост - используется для соединения двух шин PCI. Две и более шины PCI применяются в мощных серверных платформах - дополнительные шины PCI позволяют увеличить количество подключаемых устройств.
Автоконфигурирование устройств (выбор адресов, запросов прерывания) поддерживается средствами BIOS и ориентировано на технологию Plug and Play. Стандарт PCI определяет для каждого слота конфигурационное пространство размером до 256 восьмибитных регистров, не приписанных ни к пространству памяти, ни к пространству ввода-вывода. Доступ к ним осуществляется по специальным циклам шины Configuration Read и Configuration Write, вырабатываемым контроллером при обращении процессора к регистрам контроллера шины PCI, расположенным в его пространстве ввода-вывода.
В состав шины PCI введены сигналы для тестирования адаптеров по интерфейсу JTAG. На системной плате эти сигналы не всегда задействованы, но могут и организовывать логическую цепочку тестируемых адаптеров.
Шина PCI все обмены трактует как пакетные: каждый кадр начинается фазой адреса, за которой может следовать одна или несколько фаз данных. Количество фаз данных в пакете неопределенно, но ограничено таймером, определяющим максимальное время, в течении которого устройство может пользоваться шиной. Каждое устройство имеет собственный таймер, значение для которого задается при конфигурировании устройств шины.
В каждом обмене участвуют два устройства - инициатор обмена (Initiator) и целевое устройство (Target). Арбитражем запросов на использование шины занимается специальный функциональный узел, входящий в состав чипсета системной платы. Для согласования быстродействия устройств-участников обмена предусмотрены два сигнала готовности IRDY# и TRDY#. Для адреса и данных на шине используются общие мультиплексированные линии AD. Четыре мультиплексированных линии C/BE используются для кодирования команд в фазе адреса и разрешения байт в фазе данных.
Шина имеет версии с питанием 5 В, 3.3 В. Также существует универсальная версия (с переключением линий +V I/O c 5 В на 3.3 В). Ключами являются пропущенные ряды контактов 12, 13 и 50, 51. Для 5 В-слота ключ расположен на месте контактов 50, 51; для 3 В - 12, 13; для универсального - два ключа: 12, 13 и 50, 51. Ключи не позволяют установить карту в слот с неподходящим напряжением питания. 32-битный слот заканчивается контактами A62/B62, 64-битный - A94/B94.
В отличие от адаптеров остальных шин, компоненты карт PCI расположены на левой поверхности плат. По этой причине крайний PCI-слот обычно разделяет использование посадочного места адаптера с соседним ISA-слотом (Shared slot).
Шина PCI являлась до последнего времени второй (после ISA) по популярности применения. В современных системах происходит отказ от шин ISA, и шина PCI выходит на главные позиции. Некоторые фирмы для этой шины выпускают карты-прототипы, но, конечно же, доукомплектовать их периферийным адаптером или устройством собственной разработки гораздо сложнее, чем карту ISA. Здесь сказываются и более сложные протоколы, и более высокие частоты (8 МГц у шины ISA против 33 или 66 МГц у шины PCI). Также шина PCI обладает плохой помехоустойчивостью, поэтому для построения измерительных систем и промышленных компьютеров используется все еще относительно редко.
На некоторых системных (материнских) платах имеется небольшой разъем, который называется Media Bus. Он расположен позади разъема шины PCI одного из слотов. На этот разъем выводятся сигналы обычной шины ISA, и предназначен он для того, чтобы на графическом адаптере с шиной PCI можно было разместить и недорогой чипсет звуковой карты, предназначенный для шины ISA. Этот разъем, а тем более и такие комбинированные аудио-видео карты, широкого распространения не получили.
ЗАКЛЮЧЕНИЕ
С самого развития и до сих пор шина ввода/вывода является узким местом современных персональных компьютеров, что отрицательно сказывается на общих скоростных характеристиках системы. Появлялись новые шины, увеличивалась разрядность, быстродействие шин, их пропускная способность. Но разработки новых стандартов шин продолжаются. Многие фирмы объединяют свои усилия для разработки новых стандартов.
На примерах существующих стандартов видно, что у каждого стандарта шин есть свои достоинства, но есть и свои недостатки. Одни шины позволяют получать вполне удовлетворительное быстродействие, но очень дороги и сложны в изготовлении, и зачастую затраты не окупаются. Другие дешевы, но очень требовательны к системе в целом.
Список использованных источников
1. Информатика: Практикум по технологии работ на компьютере: Учебное пособие для вузов / Под ред. Н.В. Макаровой. – М.: Финансы и статистика, 1997. - 384 с.
2. Могилев А.В. и др. Информатика: Учебное пособие для студентов пед. вузов / А.В. Могилев, Н.И. Пак – М.: Академия, 1999. – 816 с.
3. Острейковский В.А. Информатика: Учебник для технических вузов – М.: Высшая школа, 1999. – 511 с.
4. Информатика: Базовый курс: Учебное пособие для втузов / Под ред С.В. Симоновича – СПб. : Питер, 2003. – 640 с.
5. Хохлова Н.В. и др. Информатика: Учебное пособие для вузов / Н.В. Хохлова, А.И. Истеменко, Б.В. Петренко. – М.: Высшая школа, 1990. – 195 с.
Шини розподіляються на ряд локальних шин , кожна... такої мікросхеми. Крім того, відновлення стандарт ів периферії відбувається дуже часто...


